If you enjoy cooking, you might be familiar with a book called the Flavour Bible. You can look up an ingredient and find lists of other ingredients that go well with it, with an emphasis on interesting or unusual combinations. It’s an amazing resource for discovering creative combinations of ingredients.
In this series of posts, I’ll try to create something similar using a dataset of ingredient lists and their ratings.
My questions are:
- How well does ingredient composition predict the rating of a recipe?
- Which individual ingredients contribute to high and low scores?
- Which combinations of ingredients contribute to high and low scores?
- Can we use all of this to identify less common but promising combinations of ingredients?
This first post will focus on exploring the dataset and the second post will use some simple modeling to delve more deeply into how ingredient composition influences the rating of a recipe.
About the dataset
I scraped the Desserts collection from the recipe website Taste to collect recipe names, ratings, and ingredient lists for 4801 recipes. The rating is the average rating given by users for each recipe and is on a five-point scale. As well as scraping the average rating for each recipe, I also collected the number of ratings. This will be important because ratings that come from a small number of reviews will be less reliable.
My metric for the quality of a dish is the rating of the recipe, but this has some problems that are worth stating up front. Firstly, in this analysis I only consider ingredient composition, but clearly there are other factors that contribute to the success or failure of a recipe. For example, a recipe that is very time-consuming or poorly written might be rated poorly despite having a delicious-sounding ingredient list. Secondly, I assume that the ratings come from people who have made the recipe as written. If you’ve ever read the reviews on a recipe website, you’ll know that this is a big assumption. It’s common for people to substitute one (or many) ingredients and rate the dish they made rather than the dish the recipe is for. Finally, it’s possible that people are more likely to leave a rating if they really like or dislike a recipe, which will affect the distribution of ratings.
You can find the code I used to scrape and clean the recipes data here. I performed some cleaning to remove quantity information from strings (for example, “1 cup flour” became “flour”) and to standardise ingredient names (“egg yolk”, “egg, beaten”, and “free-range egg” all became egg, etc).
An initial look at the data
Let’s take a look at the distributions of ratings and number of ratings:

You can see immediately that there are a lot of recipes with a rating of zero. It turns out that all of the recipes rated zero have no ratings at all. For the remaining recipes, the distribution is very skewed to the right. A surprising number of recipes have scores at or close to 100. One possibility here is that most recipes with a score of 100 have very few reviews. This could also explain the spikes at 60, 80, and 90.
We also see that there are many recipes with no or very few reviews and a much smaller number that have a lot.
Since we have the ingredient lists for each recipe, let’s also look at the number of ingredients in each recipe and the number of recipes each ingredient appears in (note the log scale used for the right plot):

The median number of ingredients is 8, and the range is from 1 to 30.
There are a lot of ingredients that appear in only one recipe and some that appear in over 1000. Since this is a collection of dessert recipes, the most common ingredients are things like caster sugar, eggs, and butter.
At this point, we have 4801 recipes and 2980 unique ingredients.
Filtering the data
Our initial look at the data revealed some potential problems:
- Many recipes with no rating. These recipes won’t be useful in determining how ingredient composition relates to rating.
- Many ingredients that appear in one or few recipes. Even if 100% of recipes containing an ingredient are very highly rated, we can’t be confident that the ingredient is really driving this if the number of recipes is small.
- Many ingredients that are extremely common. I’m mostly interested here in somewhat unusual combinations, so finding that the combination of eggs and flour contributes to a high score in dessert recipes isn’t what I’m looking for.
- There’s a huge number of ingredients (predictors) relative to the number of recipes. This will make modeling quite difficult.
Before proceeding with any analysis, I decided to filter out recipes with fewer that eight ratings and any ingredients that appear in fewer than four recipes. This left 708 recipes and 141 ingredients. This reduced list of ingredients will be easier to handle in the modeling phase.
Let’s take another look at the distributions of ratings and number of ingredients per recipe:
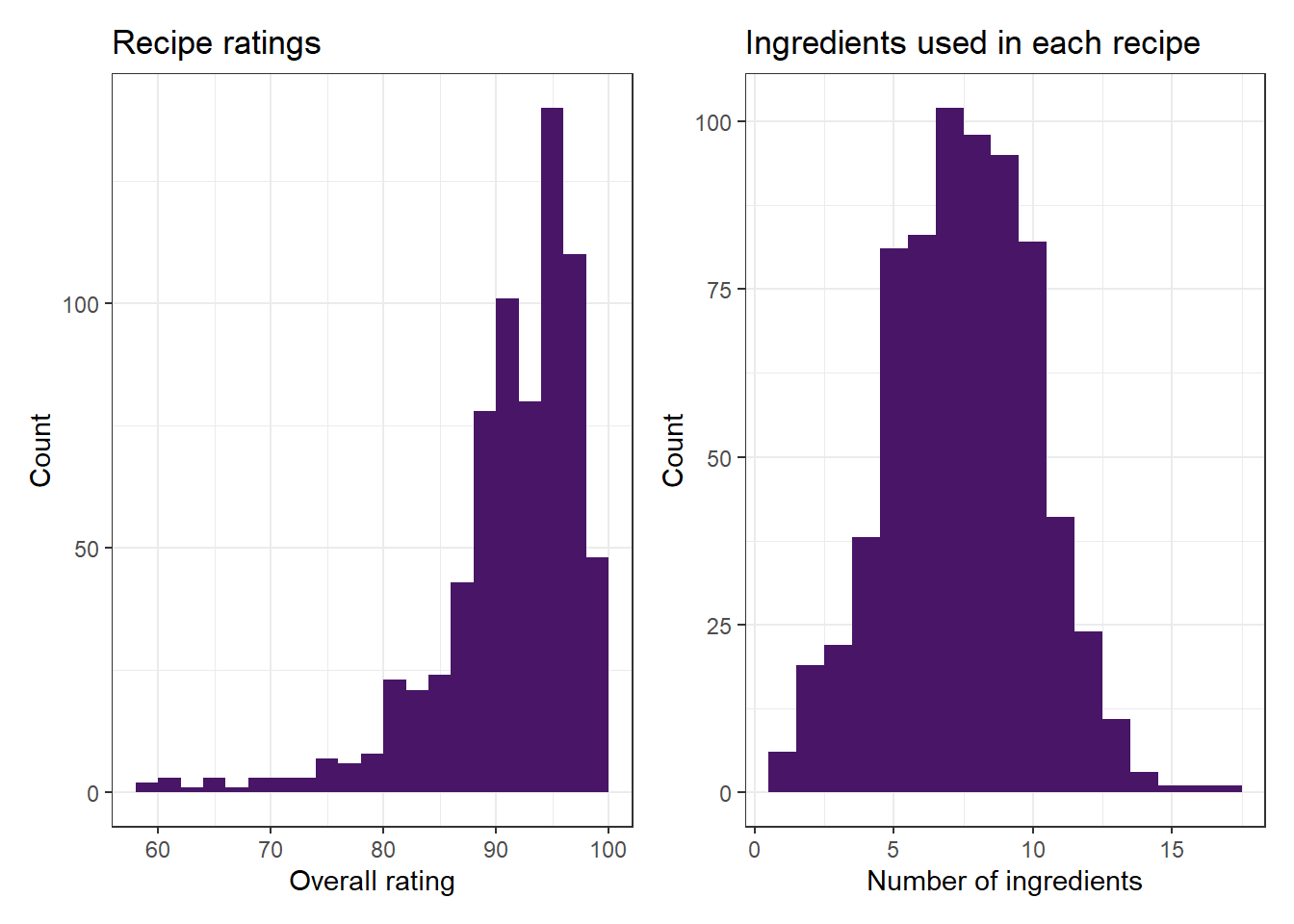
Following this filtering, the distribution of recipe ratings is still skewed to the right but not longer has spikes at 100 and 0. The median number of ingredients is still 8, and the range is from 1 to 17. It’s good to see that removing the rare ingredients hasn’t dramatically changed the distribution of number of unique ingredients per recipe.
Which ingredients contribute to higher ratings?
We’ll explore a more sophisticated way to identify ingredients that drive high ratings in the next post, but for now we’ll take a crude look at how different ingredients affect ratings.
For each ingredient, I’ve calculated the average rating for all recipes containing that ingredient. We can then compare with the average rating for all recipes. Here I’ve excluded ingredients that are very common, like butter, sugar, and eggs.
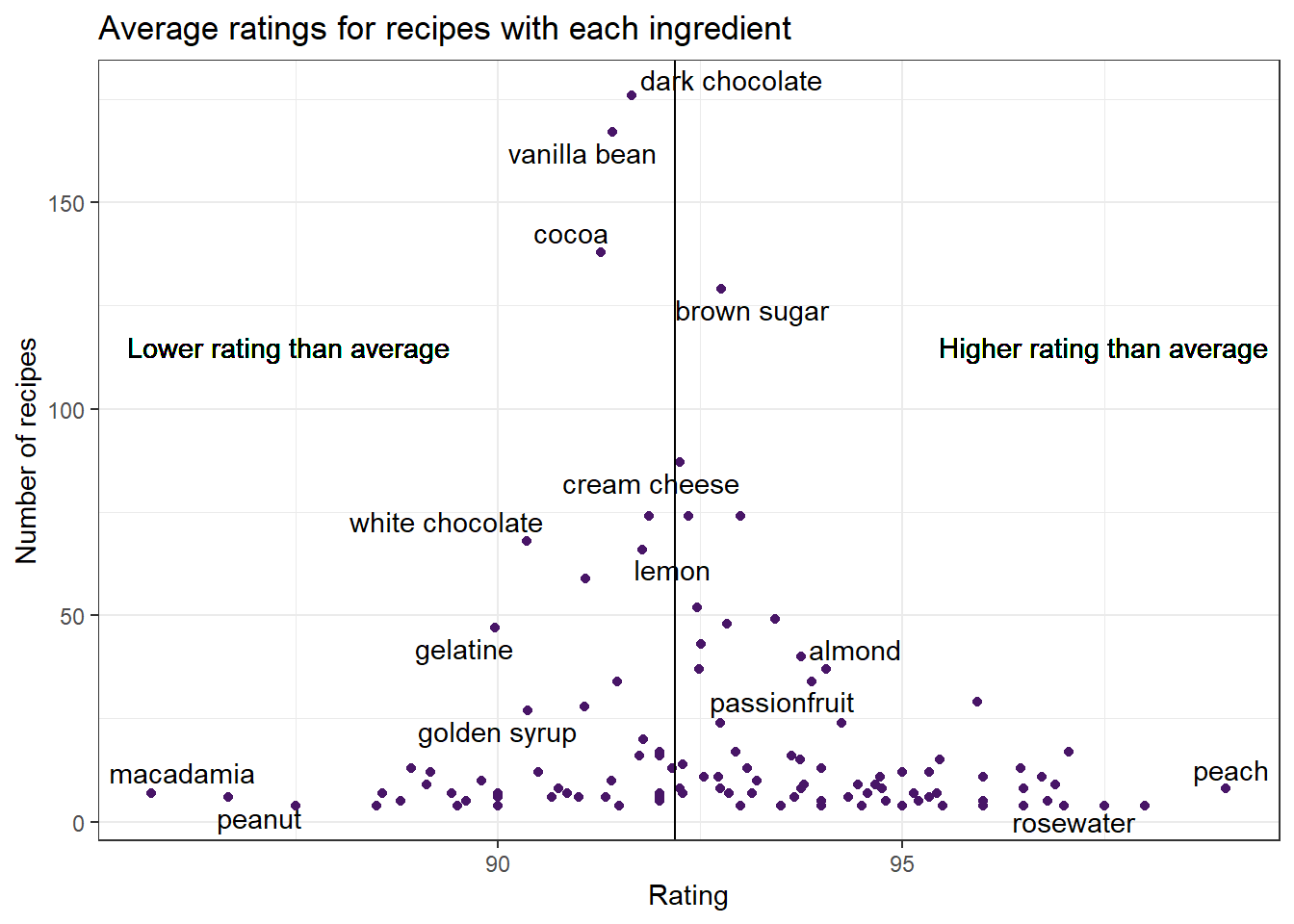
The average rating for recipes containing the ingredient is shown on the x-axis and the number of recipes with the ingredient is shown on the y-axis. We see the greatest spread in ratings amongst ingredients that appear in few recipes, which makes sense. These average ratings are less reliable because they’re based on fewer recipes. In contrast, the ingredients that appear in the most recipes are generally quite close to or slightly below to the average rating for all recipes.
One problem with analysing recipe composition in this way is that it doesn’t account for the possibility that some combinations of ingredients are more likely to occur together, which makes it harder to identify which is driving a high or low score. The approaches we’ll try in the following post will address this, but this initial visualisation already gives us some clues about what we might find.
Which combinations of ingredients are most common?
Although looking at individual ingredients can give us some insights, combinations of ingredients are what I’m particularly interested in. To keep things (relatively) simple, the analysis will be limited to pairs of ingredients.
What are the most common combinations of ingredients in the dessert recipes dataset?
There are 2941 pairwise combinations of ingredients that appear in the recipes, though 1250 appear in only one recipe. In the above table I’ve again filtered out very common ingredients like eggs and sugar. At the top of the list we have fairly obvious combinations like cocoa and dark chocolate, but the combinations get a bit more interesting as you move further down the list (like mango and sweet sherry).
What’s next?
Now that we’ve explored the dataset, the next step will be to try to make a model that links ingredient composition to a recipe’s rating.